
is this a joke: Setup, Deployment and Website Architecture

Edit (4/20/2021): The downside to deploying a large language model as cheaply as possible is that the site will crash with just modest usage or go down because it’s a preemptible instance. If the link to the website doesn’t work and you’d really like to see it, try again later. I’ll keep putting the website back up.
This article will take you through the steps to deploy a website that hosts a deep neural net (GPT-2 medium). For more information about what this website is, please read this brief writeup. You will need to supply your own GPT-2 medium fine-tuned checkpoint file, but other than that what follows is a self-contained demonstration that will result in a relatively cost-effective and easily customizable website serving a large language model that runs on a GPU.
The first section describes the architecture of the website and provides a demo video. The second section will take you through the setup and deployment of the website.
Website Architecture
Before you jump into the setup, you probably want to know a bit more about what it is you’d be building. The website itself is a simple single page application hosted on the Google Could Platform running on a virtual machine instance on a compute engine. The backend is built with FastAPI, the frontend with Streamlit. You can find the code here.
Information flow
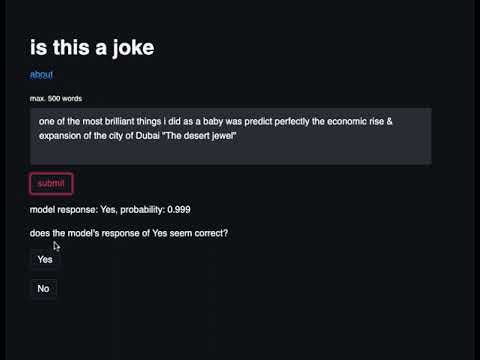
The user will arrive to a simple page with only a title, an ‘about’ link—which links to my Substack writeup on the website—and a text field under which there is a submit button. When a user submits text, it is sent to the backend via a post request and is routed to the handle_tests function. handle_tests calls predict which will return the model’s guess and the associated probability. This result is sent via a post request back to the frontend and displayed to the user who is prompted to provide feedback using one of two buttons labeled ‘yes’ and ‘no’. If the user clicks one of the buttons, their response—along with their submitted text and the model’s guess—is sent to the backend via a post request where it is saved in the user_tests folder and a ‘thank you’ message is displayed to them.
Setup and deployment
Google Cloud SDK and Project Creation
Install gcloud on your machine, go through the authentication process and create a project.
Google Cloud Virtual Machine
In your project, you’ll create a virtual machine (VM) instance. You can create this VM with either a gcloud terminal command or through the Google Cloud Platform console interface. This tutorial is based on a VM instance with the following specifications (which are among the cheapest GPU-enabled options Google Cloud offers):
Machine configuration: n1-highmem-4 (you might be able to get away with a standard memory option, n1-standard-4. You can change this by editing your instance after you’ve created it if you want to experiment.)
GPU type: Tesla T4
Operating system: Ubuntu 18.04, 100G
Firewall: allow both HTTP and HTTPS traffic
Preemptibility: You probably will have to make this instance preemptive, which is the cheap option. I haven’t been able to successfully request a non preemptive instance with these other specs. This field is tucked away under the “Management, security, disks, networking, sole tenancy” link below the HTTP/HTTPS selection boxes.
Add a firewall rule allowing all ingress traffic through port 8501 (tcp).
Basic installations
Go through google’s authentication process. Start your instance and connect to your new instance via SSH. Install updates.
gcloud compute instances start [instance-name]
gcloud compute ssh [instance-name]
sudo apt-get update
sudo apt-get upgradeDownload CUDA drivers
The following preinstallation steps can be found here. This tutorial is based on installing CUDA drivers version 11.0.3.
Preinstallation steps:
Verify that your GPU is CUDA-capable.
lspci | grep -i nvidiaCheck to see if gcc compiler is installed.
gcc --versionIf it’s not, run the following.
sudo apt-get update sudo apt-get install build-essentialRun the following to confirm installation was successful.
gcc --versionInstall kernel headers and development packages for the currently running kernel.
sudo apt-get install linux-headers-$(uname -r)
Download and install CUDA drivers
The commands to download and install the correct drivers can be found here. You don’t need to change the target platform, just scroll down to the base installer installation instructions box and run the commands.
After running those commands, verify that the drivers successfully installed.
sudo nvidia-smiThis command should produce:

Install Docker
Follow these instructions. Once you’re done, remember to add yourself to the docker group.
sudo groupadd docker
sudo usermod -aG docker $USERLog out, and log back in for the changes to take effect. You might need to reboot.
Install docker-compose
For this tutorial, you will need to install docker-compose version 1.20.0. The following two commands are taken from the official docker-compose docs under the Linux tab. I’ve customized them here for version 1.20.0.
Execute these two commands.
sudo curl -L "https://github.com/docker/compose/releases/download/1.20.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-composesudo chmod +x /usr/local/bin/docker-composeVerify that docker-compose was successfully installed.
docker-compose --versionThis command should display the correct version (1.20.0) along with the build number.
Install NVIDIA-docker
Use this official guide, starting at Setting up NVIDIA Container Toolkit under the Ubuntu/Debian section.
Pull website repository
To get my website code, run the following.
git clone https://github.com/credwood/ironyIn the root directory of the cloned code (irony), add a directory called user_tests.
cd irony
mkdir user_testsNext, add a folder called models in the backend folder.
cd backend
mkdir modelsTransfer your fine-tuned GPT-2 medium weights into this models folder.
While still in the backend folder, change the name of the file loaded by the function load_model in inference.py. The name of the file is currently gpt2_medium_joke_50bs-8.pt but it should be the name of the weights file you just transferred into the models folder.
Build and Deploy the Website
From the website’s root folder (/irony), run the following.
docker-compose buildIf it successfully builds, you can deploy.
docker-compose upOr you can run this command in the background.
docker-compose up -dDocker-compose compatibility with NVIDIA-docker
It took some testing to figure out how to get docker-compose, NVIDIA-docker, Ubuntu 18.04, PyTorch 1.7.0 and the Tesla T4 GPU to work in harmony. I ran into an incessant ‘No CUDA device detected’ error whose solution turned out to be a balance of software versions: for the Tesla T4 and the project’s PyTorch version, I needed to use docker-compose version 1.20.0 with compose format 2.3 to add NVIDIA container runtime to the docker-compose.yml file.