“Sports Twitter” Conversation Analysis with Autoregressive Classification and Zero-shot Transfer Testing

This blog post is structured as independent parts. If you’re interested in my project’s story and my (brief) thoughts on ethics in machine learning/artificial intelligence (ML/AI) start with part 1. If you just want the code and/or the data skip to part 2. If you came for the results of the title of the post and to know what future iterations of the project could look like part 3 is for you. If you want to know how I did this whole project for less than $40 with Colab and Colab Pro my suggestion would be part 4. If you want to read part 2 or 3 but are completely new to ML/AI, I would suggest skimming the Miscellaneous Definitions section in the appendix for a list of ML/AI terms. Mix and match as you please.
Part 1: Twitter, AI and Anti-dialectics
Project trajectory
Twitter as the Anti-dialectic?
Twitter’s engagement features incentivize over-the-top personal attacks and doubling down with your tribe against outsiders.
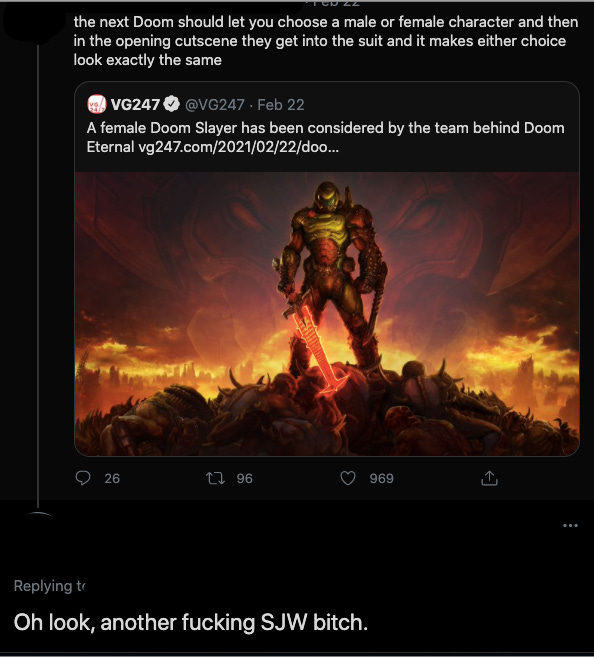
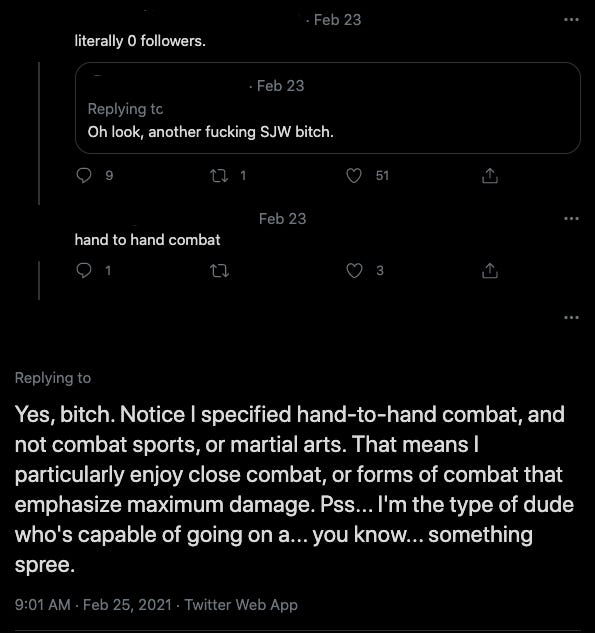
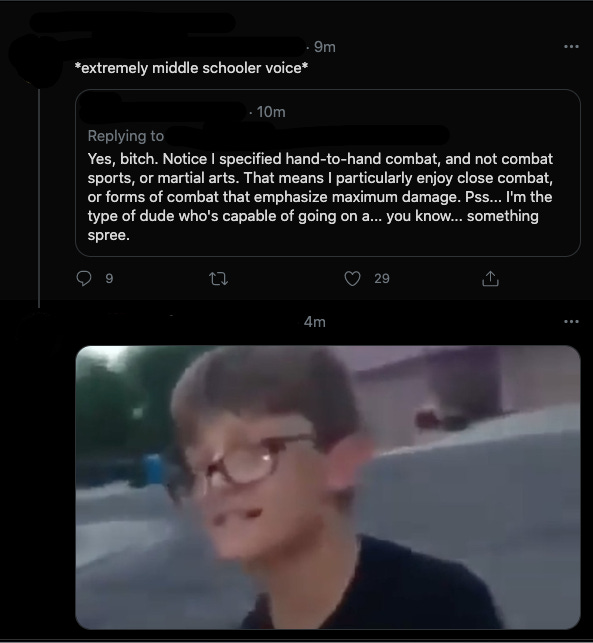
Presumptions of bad faith abound.
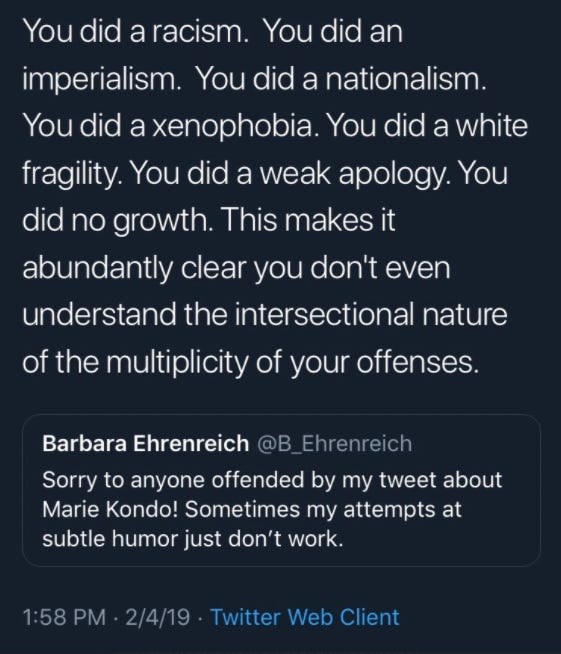
With these techniques, users build an audience and their brand on the platform. In a country with people increasingly relying on GoFundMe, Patreon and OnlyFans to survive, the incentive to engage in these behaviors to build a following that may forestall financial ruin is only growing.
Productive discourse involves the synthesis of ideas through good faith engagement. A stream of short, snippy context-free remarks thrown around back and forth by strangers who could have wildly different priors is not where good faith is found in abundance. My initial motivation for this project was to create an intervention for highly combative exchanges to diffuse bad situations before they get worse and perhaps even to encourage good faith engagement. I spent the first few weeks of this project considering the safety risks of possible interventions and concluded that what I was considering (e.g. identifying my intervening account as a bot and tweeting a note to suggest taking a breath or some such thing) were within the bounds of what people expect to experience and see on Twitter and wouldn’t be unsafe or an invasion of privacy. See the section on ethics for more information.
Twitter (Thesis) + GPT-2 (Antithesis) = Civil Discourse (Synthesis)?
My adviser—a person I had worked with in the past who offered to help me out with this project—and I decided that the first step in this process is to attempt to use a language model (GPT-2) to predict what side of an issue in a conversation a person is on; what their sentiment is, how passionately they’re engaged around the issue, and whether they’re being sarcastic or trolling.
So we have a classification problem. This is where the notions of templates and tokenization and fine-tuning models come in, but really the technical question is: can we format text inputs —conversations along with a question and its answers—in such a way that if we feed a bunch of them into the language model it can eventually learn how to correctly predict the answer to a question in an input that doesn’t already have the answer attached—and that the model hasn’t seen before—by generating the word most likely to come after the last word in the input?
Why “Sports Twitter”?
The main goal of this project was to get me—a total ML/AI novice—experience in the field. The last thing we wanted was to do something controversial and agreed it would be best to stay away from subjects (i.e. politics; identity-based or otherwise) that could derail this main goal. Instead, could we find a low stakes subject about which people get into intense fights and use it as a toy example?
“Sports Twitter”—a feisty group—seemed like it could fit that description. People from many backgrounds pulling passionately for their teams and players while dumping passionately on yours. I suspected that its lively and diverse attributes might provide interesting classification opportunities while also being a low stakes toy model of higher stakes political discourse. I thought that there would be a decent amount of conversations about purely sports that devolve into bitter attacks but that don’t touch on politics or race, subjects I wanted to avoid.
Expectations vs. Reality
I’ve been using twitter to follow the NBA and NFL for years. I thought I knew the communities and their linguistic traits, how people troll and the current memes. I felt confident that I had the breadth of knowledge both of these groups of users and the sports themselves to generate a well-labeled dataset. I expected that a somewhat meaningful portion of the Twitter conversations I found would be over-the-top, combative ad hominem attacks. To avoid conversations involving race and politics I filtered on relevant keywords (e.g. BLM, Trump, race, etc.). Perhaps because of this—and/or because of Twitter’s increased vigilance in content moderation this past year—I collected so few of what I considered to be hostile exchanges that two of my questions about trolling and tone were rendered irrelevant. I thought I would see conversations about purely sports devolve into bitter and hateful attacks, but my (somewhat sincere) working hypothesis of why I didn’t is that often when this happens race and politics invariably make their way into the conversation and therefore fell prey to my filters.
But also, if these vicious Twitter conversations about sports ever existed, Twitter’s increased content moderation strategy perhaps played a role in not capturing them. I would expect Twitter’s increased rate of banning and suspending accounts that spam and harass other users to have filtered out many of the hostile conversations I thought I’d see.
Another factor could have been that I ignored quote tweets. Quote tweeting somewhat recently became the preferred way to dunk on people and to start fights as it allows a user’s followers to see who they should dog-pile. Changing the collection strategy to focus on quote tweets might produce a more combative dataset, although I wouldn’t count on it.
Additionally, I didn’t come across enough conversations that contained what I detected as sarcasm with which to meaningfully fine-tune a model as I had planned. In the end, perhaps because of my collection strategy, three of the questions I went in hoping to work with were made irrelevant. For more information on the questions and the dataset, see part 2.
One potential caveat: I used Twitter’s free API streaming service, which (they say) gives access to a random 1% subset of live tweets. Perhaps the enterprise API would have produced different results.
I Did a Growth
For a variety of reasons, including the somewhat surprising dataset, my perspective on Twitter changed. For productive discussions on heated issues over which there is real conflict, people need to be in physical and emotional spaces that social media definitionally can’t provide: frequent physical proximity with the necessity of—or at least an incentive for— fitting into each other’s lives. Twitter is good for ephemeral coordination and reifying and amplifying existing beliefs and group identities which at times can be important use cases. Beyond that, since Twitter is getting better at banning outright threatening accounts, if people really want to have hostile and unproductive arguments that are ostensibly about politics I hope they enjoy themselves.
The initial solution I proposed to the issue now seems like a category error. Trying to make Twitter into something it’s not is a waste of time. I would encourage anyone who wants to avoid bad faith discussions to just log off. Perhaps log on to make some jokes and talk about sports or other low stakes topics with internet friends. But really do whatever you want.
And Then I Did a Pivot
Note: ML/AI terms are used in this section. I’m giving very (very) informal definitions as bolded parentheticals, but please see the Miscellaneous Definitions section in the appendix if you want more precise definitions.
My evolving thoughts about Twitter and its place in discourse resulted in my interest in content moderation flagging significantly. I decided that it would be interesting instead to change the focus of the project to see how classifiers trained on one dataset transfers to other datasets.
I was interested to see how GPT-2 medium* fine-tuned (tailoring a model that’s already seen a decent amount of—likely diverse—data to a specific task by showing it examples of the task) on the sentiments of people talking about sports on Twitter—often ambiguous and requiring contextual clues—would transfer (taking a model trained with certain data and testing it on something else) to data generated to explicitly label and express sentiment about an explicit thing, and vice versa.
As it turns out, pretty well. Perhaps because my dataset isn’t big enough, or perhaps because of limitations in computing resources I used for the project, the fine-tuned language model (a wonderful thing that gives predictions for subsequent words in a text. In GPT-2’s case this is based only on the words in the text that came before, there’s no peeking ahead) didn’t get particularly good at classifying Twitter conversations even though it was fine-tuned on this task (correct at a clip of around 62%), but it did do well at classifying Yelp reviews without having been fine-tuned on this task (correct over 84% of the time). The model fine-tuned on Yelp reviews was pretty good at classifying the sentiment of unseen Yelp reviews (correct 92.5% of the time) but not great at classifying the sentiment of Twitter conversations (correct 40% of the time). If you’re interested in the details, please see part 2.
*medium refers to the size of the model. GPT-2 medium has 345 million model parameters (the bits of the model that are tweaked during training/fine-tuning; the things that learn))
Ethical AI and the Ethics of this Project
Even though my interest in content moderation waned, I still think work on radicalization and polarization is crucial. My solution of telling people to log off unless they want to make jokes or talk about sports is more a philosophical than a practical one.
A large part of dealing practically with these issues is addressing algorithmically generated echo chambers. There are plenty of people who are doing great work in this area. If you’re new to data ethics, I’d suggest Rachel Thomas’s data ethics course. The Algorithmic Justice League is a good resource for bias in ML/AI models.
My initial goal was to help people engaged in vicious fights on Twitter come to a synthesis of their ideas or at least to de-escalate the situation. But what if I had implemented this hypothetical intervention and somehow it ended up doing the opposite? Or what if someone were to get access to my dataset and use it to train a larger model than I worked with, get better results and use it to to exploit people in some way? The first thing I did when we started the project was to outline and explore the risks and unintended consequences of this project. Here is a short document I drafted during this process that touches on why this intervention would have been safe and why I could proceed without informed consent. Anyone interested in using the pipeline I built would have to agree to Twitter’s ToS, so given that I think it’s safe to make it publicly available which I have done here. If you want access to my labeled dataset first make sure you agree to the Twitter Terms of Service, Privacy Policy, Developer Agreement, and Developer Policy and then get in touch with me about it.
My initial intention may have been flawed, but I’m genuinely happy with this project. If you have good faith critiques of the ethics of giving individuals access to the pipeline or labeled data, please let me know.
Part 2: The Code and the Data
The Twitter Conversations Dataset
Over the course of a few weeks in fall of 2020—around the time the NBA had it’s bubble playoffs and just as the NFL season was starting—I collected and labeled around 1,200 sports-related Twitter conversations. You can find my code for collecting conversations, fine-tuning and conducting zero-shot transfer tests with OpenAI’s GPT2-medium model (with Hugging Face’s transformer library) here.
The data is stored in JSON lines files as python dataclasses called Conversations. Each Conversation contains the following fields (field names in bold):
The conversation thread, a list of Tweet dataclasses which themselves contain user/tweet data
A list with the five labels for each question along with the topic
The conversation template which is automatically generated upon collection and can be revised later. (“Template” is a misnomer, as this field contains a rendered template.)
The handle_tested, the subject of the templated question
An empty list for prediction or fine-tuning statistics, model_statistics
For an example of these dataclasses, see the Conversation and Tweet Dataclasses section in the appendix. If you want access to the labeled dataset first make sure you agree to the Twitter Terms of Service, Privacy Policy, Developer Agreement, and Developer Policy and then get in touch with me about it.
Collection and Labeling Methodology
To collect the data, as NFL and NBA games, trades or beefs were unfolding I would use a function called get_conversations—which you can see in my github repository in this file—to keyword search for relevant conversations and I would label them more or less immediately with the context in mind, although I ended up re-labeling the data three separate times as the goals of the project changed. In the end, for each conversation, I considered five separate questions which address:
Affinity for the topic/team/person
Sentiment about the topic/team/person
Tone of interaction (i.e. is it an argument, discussion or strong agreement)
Whether the user is a troll
Whether the user is being sarcastic.
For more information about the questions and the labeling methodology please see this document.
Yelp-2 Dataset
After a review of the literature on conversation analysis with autoregressive models, it seemed like the second question addressing sentiment would provide the most interesting zero-shot transfer testing opportunities. I came across this blog post which is based on this paper, “Zero-shot Text Classification With Generative Language Models” (Puri et al., 2019) which tests the zero-shot transfer from fine-tuned GPT2 models to different benchmarking datasets, including Yelp-2.
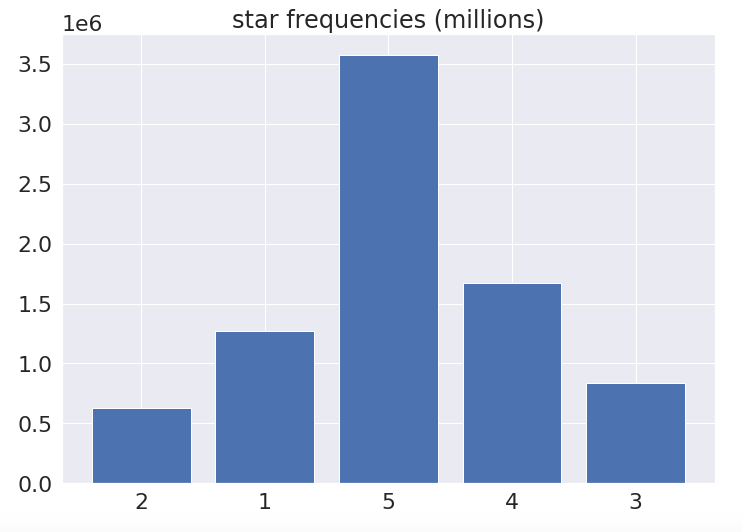
Yelp-2 contains approximately 8 million reviews, each of which consists of a star rating (one through 5) and a written review. I was interested to see how GPT-2 medium fine-tuned on the sentiments of specific people about specific topics in Twitter conversations—largely ambiguous and requiring contextual clues—would transfer to data generated to explicitly label and express sentiment about one thing, and vice versa.
Part 3: Fine-tuning Process and Zero-shot Transfer Results
I used Colab Pro for all fine-tuning tasks and zero-shot transfer testing. For a rundown of how that worked for me, please see part 4.
Yelp-2 Reviews and Question 2 Templates
To create the respective rendered templates, the end prompts are added to the end of the conversations/reviews. The fine-tuning rendered templates also include the natural language label, the validation templates do not.
Yelp-2
End prompts:
The end prompt used for zero-shot transfer testing is:
Q: Is the sentiment in this review positive, negative or neutral?
A:
The end prompt used for fine-tuning is:
Q: Is the sentiment in this review positive, negative or neutral?
A: [Ground truth label]
I bucketed the Yelp-2 dataset into three classes based on the numeric star rating. The natural language labels are: 1-2: “ Negative”, 3: “ Neutral”, 4-5: “ Positive”.
Example of a rendered template for fine-tuning:
Our daughter has attended the ACT Prep program at Huntington and the results we awesome! Her ACT scores improved from 4 to 8 points across the different testing areas. The instructors are outstanding and very professional. We highly recommend the Huntington Learning Center.
Tim and Debbie
--
Q: Is the sentiment in this review positive, negative or neutral?
A: Positive
Twitter Conversations (Question 2)
Conversations labeled for question 2 were originally rated with one of 6 numeric values, but I’ve filtered out the conversations that can’t be bucketed into a negative, positive or neutral rating so that both datasets have the same classes.
End prompts:
For zero-shot transfer testing, the end prompt is:
Q: Is {name}’s sentiment about {topic} positive, negative or neutral?
A:
For fine-tuning, the end prompt is:
Question: What is {name}’s sentiment about {topic} in this conversation?
Answer: [Ground truth label]
Example of a rendered template for zero-shot testing:
MagicJohnson: The @Lakers are now tied with our heated rivals the Celtics with 17 NBA World Championships! 🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆🏆💍💍💍💍💍💍💍💍💍💍💍💍💍💍💍💍💍
Celtics_Col: @MagicJohnson @Gjgsf27 @Lakers MINNEAPOLIS LAKERS 🤝 LA. LAKERS 17🏆💍
CELTICS 17🏆💍
bradstevi: @Celtics_Col @MagicJohnson @Gjgsf27 @Lakers Dang u Celtics fans are thirsty. Outlier year when yall had the nbas 1st super team and only won 1. Take that away abs you haven't been relevant since those bird years. 2 separate dynasties just be happy your team still gets mentioned.
Pesk692: @bradstevi @Celtics_Col @MagicJohnson @Gjgsf27 @Lakers Would’ve won in 2009 had Garnett not gotten injured and in 2010 had the refs not helped the Lakers rebound in the last game
bradstevi: @Pesk692 @Celtics_Col @MagicJohnson @Gjgsf27 @Lakers Woulda coulda.. injuries happen. Plus you're assuming they would've won with garnett.. games have to be played.
Pesk692: @bradstevi @Celtics_Col @MagicJohnson @Gjgsf27 @Lakers So it’s fine for you to take off the 2008 super-team, yet all of your 6 champions this century have been a result of building super teams.
bradstevi: @Pesk692 @Celtics_Col @MagicJohnson @Gjgsf27 @Lakers 1 I'm not a laker fan. 2 the teams w kobe and Shaq weren't super teams. When Shaq signed the Lakers kobe was a rookie.. nave 1 other player from those championship years that's a star.. none.. and gasol Isn't a super star. And this team that just won had only 2 superstars.
--
Q: Is Pesk692's sentiment about the Lakers positive, negative or neutral?
A:
The answer is ‘ Negative’. This Celtics fan does not, in fact, have positive feelings about the Lakers in this conversation.
GPT-2
Here is a good visual exploration of how GPT-2 works. For this portion of the project, I used the medium sized pre-trained GPT-2 model from Hugging Face’s transformers library.
Autoregression
Given an input sequence, GPT-2 generates text by guessing the next token in the sequence and attaching this output token to the end of the input to form the next input, and so on. This process is called autoregression.
Applied Autoregression
For each token in an input sequence, the model assigns a logits tensor which can be used to calculate the probability the model assigns for each word in the model’s vocabulary to be the next word.
To monitor how well fine-tuning of the classifier is going, I calculated the model accuracy on the validation data after each epoch. To this end, the most important token in the validation rendered template is the last one. This token’s logits tensor can be isolated and the softmax function can be applied which will produce a probability distribution across the model’s vocabulary. The accuracies presented in the table below consider the token with the highest probability as the model’s guess except for the row marked with “with logit masking for non-label logit values”. For these results, which consider only the class labels, non-label logits are set to -10**8, then the argmax of the softmax is taken as the model’s response. The code for this is in the predict function in sportsbot/inference.py in the repository.
Fine-tuning GPT-2
All fine-tuning was done on Colab Pro. You can find a notebook for reproducing similar results of the Twitter conversations fine-tuning and Yelp-2 zero-shot transfer testing tasks here. The training loop function is in the repository in sportsbot/finetune.py file, function parameter explanations are in the repository’s main README. For fine-tuning hyperparameters, please see the Additional Fine-tuning Details and Hyperparameters section in the appendix.
Results
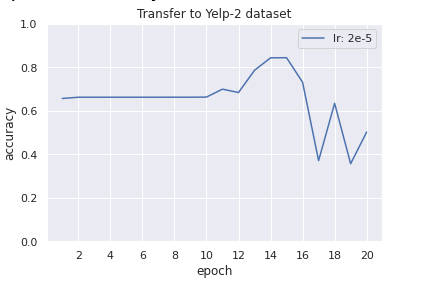
The Yelp-2 zero-shot transfer accuracy with a model fine-tuned on 704 unique Twitter conversations (1065 conversations in total, fully balanced) is 84%. Question 2 was labeled with three additional labels: “ Unsure”, “ None” and “ N/A” which were all filtered out for these fine-tuning and validation tasks. The pared down dataset used for this fine-tuning task of just “ Positive”, “Negative” and “ Neutral” examples are therefore relatively unambiguous which—along with balancing the classes in the fine-tuning dataset—at least partially explain the Yelp-2 zero-shot transfer accuracy. Label masking—setting tokens in the label tensor corresponding to the conversation portion of the template to -100 during fine-tuning—also likely helped transfer. The model is extremely bad at detecting “ Neutral” Yelp-2 examples (3 star ratings) which makes sense because people’s interpretations of what constitutes a 3 stars rating are inconsistent and also because the “ Neutral” Twitter conversations consists largely of media members tweeting out news or individuals speaking about the topic without really expressing an opinion.
The Yelp-2 fine-tuning validation is 92.5%. I didn’t balance the dataset which heavily over-represents “ Positive” reviews. The model saw approximately 6.5 million reviews during fine-tuning. See the appendix for more details about fine-tuning with this dataset.
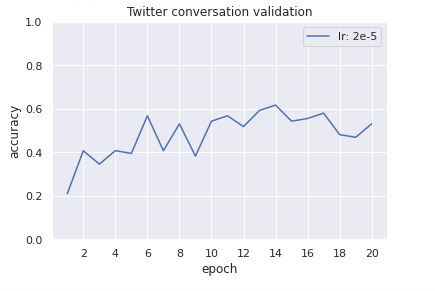
The best validation result for the Twitter conversations validation dataset is 61.7%. I think this task requires a larger fine-tuning dataset for accuracy to improve.
The Twitter conversation zero-shot transfer accuracy with the model fine-tuned with Yelp-2 data is 40.7% which is not great, but given the arg max accuracy of 12.8% (i.e. what the validation accuracy would be if the model collapsed to the dominant label in the fine-tuning data), just how skewed the Yelp-2 dataset is toward the “ Positive“ label and taking into consideration the amount of context involved in getting the question 2 prompt right compared to a Yelp review, I expected worse.

Adding Yelp-2 reviews to the Twitter conversations dataset for fine-tuning helps validation on the Twitter conversations up to a point after which the accuracy decreases.
Further Analysis: Visualizing Training Progress
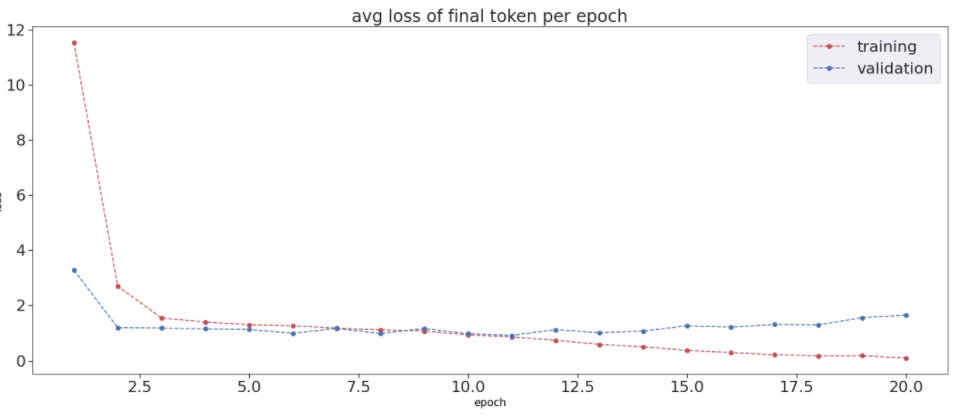
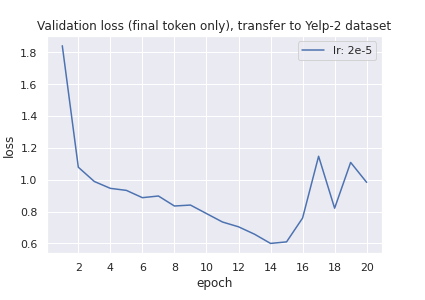
The twitter conversations validation loss (calculated during fine-tuning) begins to rise after the eleventh epoch but the Yelp-2 zero-shot transfer accuracy and the Twitter validation accuracy peak after this at basically the same time on the 14th epoch (although the 15th epoch for the transfer validation is slightly better).
The first ten epochs of the Yelp-2 zero-shot transfer accuracy validation graph is stagnant, and from the confusion matrices we see that this is because—besides an extremely small amount of model predictions in the first epoch falling in the “invalid” class—the model is collapsing on the “ Positive” label. For these ten epochs, while this transfer accuracy was stagnant, the Yelp-2 zero-shot transfer validation loss graph has an overall negative slope; transfer was improving but not enough to show up with the accuracy metric. This loss graph reaches its lowest point at the 14th and 15th epochs, then rises sharply.
Testing Yelp-2 zero-shot transfer across epochs on Twitter conversation models fine-tuned with different learning rates (not pictured) produce different (smaller, based on my experimentation) peaks at varying epochs, but they all begin with relatively static accuracies and a significant drop off after the peak.
The columns of the confusion matrices are ground truths, the rows are the model’s guesses (Zoom in on the image for better clarity):

Where to go from here
I left a lot on the table in terms of working with (and labeling) the Twitter dataset I collected and the models I used. If I were to keep going there are a few immediate next steps I would take:
Update to the newest transformers release
Hugging Face’s transformers library now allows for gradient checkpointing which means that theoretically I could fine-tune the GPT-2 XL model with 1.5B parameters on Colab. Refactoring the code to try this would be my immediate next step.
Get more out of the Twitter conversation dataset
I labeled each conversation with respect to only one of the interlocutors. I really should have created a conversation object with a template labeled for each person involved in each conversation I collected.
I only used the user names and tweet text in the templates, but I collected much more information about each user, including their profile description. It would be interesting to try to add this information into the template.
Get more out of Colab
Automating the authentication process and re-running notebook cells could allow for Colab/Colab Pro to be a viable production environment. I did this manually throughout this project but it would be worthwhile to see how robust the service can be with some dedicated development to that end.
Adding quote tweets
People use quote tweeting to dunk on each other and I think collecting these along with replies would build a robust dataset. For anyone interested in my initial project idea, I would suggest trying this.
Expand to other models in the transformers library
I’m not sure how much my code as-is would generalize to Hugging Face’s BERT transformers but I would invest time in refactoring for more general use of the library.
Take the leap to Google Cloud (or whatever)
Colab Pro is great and I will probably use it for a long time, but after exhausting the suggestions above I would consider leveling up and paying more for fine-tuning.
Zero-shot/few-shot testing with the GPT-3 API
Experimenting with prompt engineering for few-shot and zero-shot classification with GPT-3 for the Twitter conversations and Yelp-2 would be an interesting benchmarking exercise for anyone willing to spend money.
Part 4: Working with Colab Pro
Costs and Benefits of Using Colab Pro
Overall, using Colab Pro for this project—my first deep learning project—was a great experience and I will absolutely use it again. The primary selling points for me are the freedom it provided and the low cost for the amount of production I got. I think paying for a service per hour or based on resources used would have hindered my ability to learn and experiment with the models and data.
There are certainly downsides but for my purposes the pros outweigh the cons. You can judge for yourself:
Pros
Freedom to learn: I was able to learn how to work with the models without having a running calculation of the financial cost in the back of my head stopping me from trying tests that maybe “wouldn’t be worth it”. (Of course there’s still an environmental cost). Trying all kinds of wild and probably ill-advised tests allowed me to develop an understanding/intuition of how to tweak hyperparameters and work with the different datasets. Fine-tuning with the Yelp-2 dataset was the longest continuous task I undertook, but I spent months running many different tasks on the GPU for 12 hours a day to experiment, to get to know the model and to write my fine-tuning and inference functions.
Cheap, obviously: I only needed Colab Pro for maybe three months for this project, so at $10/month I paid around $30 dollars. A lot of this time was spent figuring out the project itself and labeling the Twitter conversations dataset and not on the transfer tasks I’m outlining in this blog. Fine-tuning those two models and running transfer tests takes two to three weeks. Colab Pro definitely isn’t necessary to collect and label a Twitter dataset or to just play around with zero-shot testing. If planned correctly, one could use the free version for most aspects of this project and pay for Pro for a month.
I also bought more storage space on Google Drive to keep many of the checkpointed weights I saved after each epoch. GPT-2 medium checkpoint files are each ~1G, and I also save json files with validation data for each epoch. This was unnecessary and one could produce the same results with far less storage space by just being more discerning about which checkpointed weights one keeps. I bought 2TB of storage which is $10/month; I only needed this upgrade for the last month of the project.
In total, I paid ~$40. If someone wanted to replicate this project, they could probably do it for less than $20 dollars.
No learning curve: There’s basically no setup required, just open a notebook, go to the Runtime tab, then Change runtime type to make sure you’re on a GPU (if that’s what you need), then start. That’s it.
Cons
Time sink: It took ten days to fine-tune GPT-2 medium with ~6.5 million Yelp-2 reviews. I couldn’t run any other inference or fine-tuning task because this used every bit of my allotted GPU memory.
Data constraints: Couldn’t fine-tune/predict with a batch size greater than 1. I ended up using the batch_size parameter in my code as a marker for the optimizer and zero_grad steps for gradient accumulation. For fine-tuning with Yelp-2, I had to limit input length to less than 512 tokens.
Performance drag: I noticed a dropoff in GPU performance after I completed fine-tuning with Yelp-2 which took me about ten continuous days. Colab mentions it allocates GPU resources based on how much someone has used recently. From the FAQ section of Colab Pro’s signup page here: “Resources in Colab Pro are prioritized for subscribers who have recently used less resources, in order to prevent the monopolization of limited resources by a small number of users. To get the most out of Colab Pro, consider closing your Colab tabs when you are done with your work, and avoid opting for GPUs or extra memory when it is not needed for your work. This will make it less likely that you will run into usage limits within Colab Pro.”
Hogging the resources for ten days resulted in CUDA memory errors from fine-tuning setups that I hadn’t previously had problems with. To solve this, I had to restart the runtime after each fine-tuning loop whereas before I could run as many fine-tuning tasks as I wanted without clearing the memory. I also experimented a bit more with template lengths to optimize the diminished GPU resources. Ultimately, I was able to make it work by keeping in mind the resources using the GPU that I had direct control over and also clearing the memory manually after computationally expensive tasks.
Disappearing instances do get annoying: Colab Pro promises instances will stay connected for up to 24 hours; for the most part I got basically what Colab Pro promises but a few times while fine-tuning with the Yelp-2 data the instance disconnected after only ~12 hours. With a meaningful naming system for checkpointed weights that told me precisely where in the dataset I should restart fine-tuning, this amounted to maybe 2 minutes of work every 20 hours or so during the Yelp-2 fine-tuning task. I did this during lockdown and for the most part I was around to restart instances immediately.
Once an instance disconnects, I have to re-authenticate using my Google account to allow reading/writing to my drive. Since this process takes maybe 30 seconds and since I was mostly at home I didn’t think trying to automate it was worth it, but perhaps one could make it so that the system automatically re-authenticates and restarts the loop after it gets disconnected. But again, this whole process took me about two minutes once a day.
Reinstalling packages every time an instance disconnects or needs to be restarted is a minor annoyance. I got used to it, but taken in aggregate it definitely added time to the project. I obsessively saved to my drive so I never had a problem with losing work.
Final Review
Paying just ~$40 for a deep learning project for which fine-tuning a 345 million parameter model with ~6.5 million records was only a relatively small part of the total GPU usage dwarfed the inconvenience of fleeting instances and somewhat unreliable compute resources.
5 stars, “ Positive”, 10/10 would use again.
Appendix
Miscellaneous Definitions
This is a non-exhaustive and not GPT-2 specific list of common terms in deep learning. Definitions are meant to be as general and basic as possible.
Language model (high level definition): a thing that gives as its output the probability distribution over its vocabulary of what subsequent tokens of an input text will be. (e.g. If you give a model “Hello, what is your”, for the last token “ your” the model might give a high probability that “ name” will be the subsequent token.)
Tokenization: map between natural language words and symbols to numeric representations (tokens).
Affine mapping: a linear map + translation.
Weights and biases (model parameters): affine maps in hidden layers that are applied to input tensors or activation layers during the forward pass and adjusted during backpropagation (defined later).
Activation function: a nonlinear function applied after an affine mapping in hidden layers.
Hidden layer: affine map and activation function
Layer: input, hidden layers, output are all layers
Forward pass: an input’s journey through a model’s hidden layers to becoming an output.
Neural network (model): a network of hidden layers through which input data gets fed resulting in an output. Each hidden layer consists of tensor operations—applied to the input or the output of the previous layer—which are affine maps (model parameters) composed with nonlinear functions and at the last layer a (likely) different activation function such as Softmax for classification problems.
Deep learning: a neural net with multiple hidden layers.
Convex function: function with no local minima, just a global one.
Loss function: (an ideally convex) function that is optimized through gradient descent throughout training or fine-tuning.
Learning rate: scaling value for loss function used for gradient descent/backpropagation (defined later).
Weight decay/L2 regularization: two ways of incorporating the model weights into the loss function to penalize overfitting and to promote weight stability (i.e. prevents weights from getting too big resulting in model divergence).
Optimizer/scheduler: an optimizer handles updating the model parameters with the gradient of the loss function. Depending on the kind, it might offer weight decay/L2 regularization. The scheduler adjusts the size of the learning rate scaling the loss function during training/fine-tuning according to a predefined schedule.
Logit: unnormalized log-probability
Softmax: activation function for classification tasks often used in the final network layer. Turns logits into a probability distribution over output classes.
One-hot encoding: vector of binary values.
Cross entropy loss: negative sum of the log of probabilities for each class multiplied by the class’s one-hot encoding.
Backpropagation: after the forward pass, the gradient of the loss function with respect to each hidden layer’s model parameters is calculated and scaled by the learning rate which might be controlled by an optimizer and a scheduler and is subtracted from the respective hidden layers’ model parameters.
Training: process of feeding data into the model so it can learn to be a human.
Fine-tuning: taking a trained model and feeding it more data to adjust the model parameters of (often) the last hidden layers of the model in order to tailor it to the fine-tuning task.
Inference: inputting data into a model to get a prediction or answer or classification or whatever you want to call it.
Downstream task: inference task that uses a pre-trained model.
Zero-shot transfer testing: running inference with a model on a downstream task without fine-tuning the model on that task.
Batch size: number of examples fed to the model at once.
Epoch: a single pass of the whole fine-tuning/training dataset through the model during fine-tuning/training.
Label masking: setting label tokens to values that will be ignored when the loss is being calculated during fine-tuning/training. Promotes generalization to transfer tasks.
Conversation and Tweet Dataclasses
The following conversation has a rendered template tailored for question 2 addressing user michaelshekar’s sentiment for the Cowboys. I rated michaelshekar’s sentiment about the Cowboys in this conversation ‘ Negative’ (question 2 labels are the second number in the label field, 10 corresponds to ‘ Negative’). michaelshekar is complaining about the refs rigging the game to help the Cowboys, the person he’s responding to (Chris Long) is a popular former Eagles’ player (division rivals with the Cowboys). I didn’t have space in the template to use the profile_description field (so I didn’t consider it during labeling), but he has #NYG which suggests he’s a fan of the New York Giants; another division rival of the Cowboys.
Conversation(
thread=[
Tweet(user_id=1315436485387194378,
user_handle='JOEL9ONE',
display_name='chris long',
content='Cowboys got away with a hold inside there and that’s a huge chunk if it stands.',
language='en',
date_time=1602459472.0,
num_followers=652476,
num_followed=2246,
profile_description='anti-robot, La Flama Blanca, Host of the Green Light Pod, 2x Super Bowl champ 💎'
),
Tweet(user_id=1315470117011152898,
user_handle='michaelshekar',
display_name='SgrA*',
content='@JOEL9ONE The entire game was called to help the cowboys win. I hate watching games like these. The refs had more to do with the outcome than any player on the field.',
language='en',
date_time=1602467490.0,
num_followers=184,
num_followed=452,
profile_description='#NYG #NYM🇺🇸🇬🇾 Fulltime Food consumer Part-time Grown-up Weekend drinker. Pro human rights anyone and everyone with exception to those who deny it to others.'
)
],
label=[1, 10, 12, 1, 1, ' the Cowboys'],
template="JOEL9ONE: Cowboys got away with a hold inside there and that’s a huge chunk if it stands.\nmichaelshekar: @JOEL9ONE The entire game was called to help the cowboys win. I hate watching games like these. The refs had more to do with the outcome than any player on the field.\n\n--\nQuestion: What is michaelshekar's sentiment about the Cowboys in this conversation?\nAnswer:",
handle_tested='michaelshekar',
model_statistics=[]
)Additional Fine-tuning Details and Hyperparameters
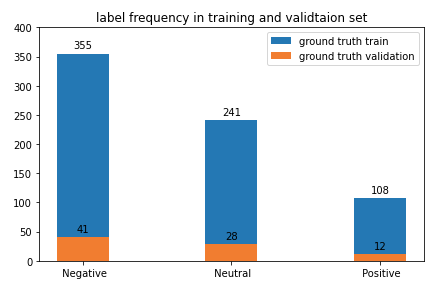
Fine-tuning dataset sizes: Twitter conversations fine-tuning dataset used for this task has 704 conversations, Yelp-2 fine-tuning dataset ended up at approximately 6.5 million.
Validation dataset sizes: Twitter conversation validation set has 81 conversations. For the results in this blog, I used 7,000 reviews from the Yelp-2 validation set.
Additional dataset comments: The Yelp-2 dataset skews overwhelmingly positive, while the Twitter conversations dataset skews overwhelmingly negative. I had to oversample positive records by a factor greater than three to balance the Twitter conversation fine-tuning dataset. I experimented fine-tuning with unbalanced Twitter conversation datasets but fully balanced seems to work the best, which is what I present in the table in the Results section. The results vary a bit depending on which conversations get over sampled most frequently. I’ve played around with it and for fine-tuning datasets that don’t produce a transfer spike into the 80% range with 2e-5 as the learning rate, I was able to find an accuracy spike over 80% with different learning rates. I got spikes into the 80% range on my first few tries and didn’t notice this behavior until recently.
Learning rate: I tested several learning rates while fine-tuning with the Twitter conversations and 2e-5 was the best. For Yelp-2, based on heuristics from extensive fine-tuning with the Twitter conversations dataset I used 2e-5 as my first guess. The primary goal of this project wasn’t to build a classifier with the Yelp-2 data and this task took so much time that I didn’t end up trying to optimize its hyperparameter.
Batch size: The gradient accumulation size throughout fine-tuning for both datasets is five and—because of Colab pro memory constraints—the batch size is one.
Optimizer and scheduler: Hugging Face’s implementation of the AdamW optimizer with weight decay set to zero and with the get_linear_schedule_with_warmup linear scheduler.
Label masking: For each fine-tuning task, I’m masking everything in the input up to the end of the actual conversation/review during fine-tuning.